
隨著大模型技術(shù)快速發(fā)展,多維視通的大模型技術(shù)也在持續(xù)研發(fā)中,并已應用于警視通視頻偵查實戰(zhàn)應用平臺,為平臺提供強有力的技術(shù)底座。

視覺多模態(tài)大模型技術(shù)是計算機視覺領(lǐng)域近年來最重要的技術(shù)突破之一,它通過大規(guī)模預訓練和 Transformer 等架構(gòu)的引入,顯著提升了模型在多種視覺任務上的泛化能力。多維視界大模型為多維視通自研大模型,包括文搜圖大模型、REID大模型、目標檢測大模型等,應用于案件理解、影像認知、偵查輔助、深偽檢驗等,為警視通視頻偵查實戰(zhàn)應用平臺等產(chǎn)品提供更先進、更有效的技術(shù)支持。
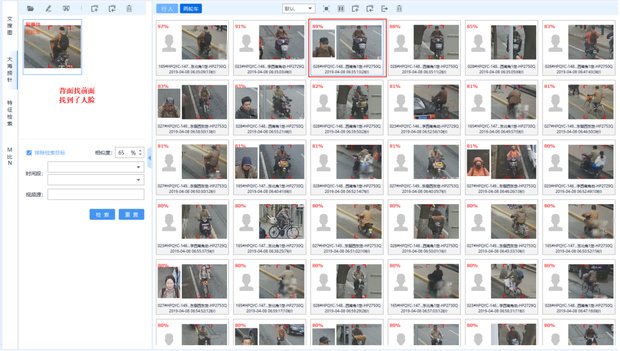
文搜圖大模型:基于自然語言描述(如關(guān)鍵詞、短語或句子)來搜索匹配內(nèi)容的相關(guān)圖像。例如,輸入“穿黑色夾克、背藍色背包的男性”,模型可跨攝像頭、跨時間段匹配目標,解決實戰(zhàn)過程中,根據(jù)目標特點尋找其軌跡的需求。

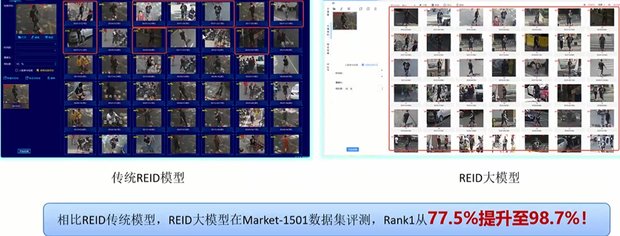
REID大模型(行人重識別):通過細粒度特征學習,實現(xiàn)跨場景、跨視角的個體追蹤。模型利用大量行人數(shù)據(jù)預訓練,即使目標更換衣物或遮擋面部,仍能通過人體、人臉互搜鎖定身份。
目標檢測大模型:支持車輛、物品、行為等多維度識別,針對場景給出專有算法或個性化參數(shù),來提升視頻計算的精確度。
如需了解產(chǎn)品等相關(guān)問題,請聯(lián)系我們。
全國統(tǒng)一服務熱線:
4008-857-785轉(zhuǎn)4、010-62670718、010-62670719
感謝您的關(guān)注與支持!


